Circular Dependencies
Introduction
Circular dependencies occur when a table references 1 or more other tables which eventually reference the original table. They can also occur when a column references another column in the same table. Neosync can handle both cases. Let's look at how we generally handling circular dependencies.
Circular Dependencies
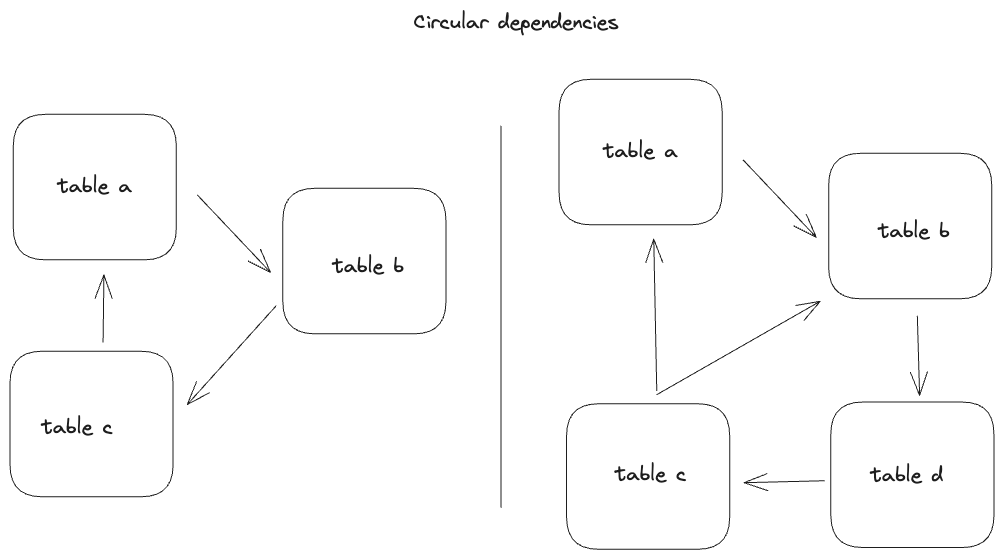
Circular dependencies across tables are pretty common in most databases and can come in a lot of difference shapes and sizes. Sometimes, it's two tables referencing each other, other times, the circular dependency can be many tables long.
Neosync tries to handle all circular dependencies natively using the following algorithm:
- Create a DAG of the circular dependency to understand which tables rely on each other.
- Find the starting point and insert primary keys and data into that table besides any foreign key references. Note that the foreign key column in the child must be nullable.
- Then continue to cycle to the downstream table from the one we just inserted to insert all of the data into that table and then continue cycling.
- Come back to the original starting table, and update in the foreign key reference into the nullable column.
This is the general approach to how we handle circular dependencies although it does get quite more complicated when we add in more tables, filters, aliases and other attributes to the mix. The key thing here is that at least one table involved in the dependency must have a column that is nullable so that we can come back to it later and fill in the remaining foreign key references.
Sync Jobs
Handling circular dependencies in a Sync Job involves a few key concepts:
Support for Circular Dependencies: Sync jobs can handle both self-referencing circular dependencies and those spanning multiple tables.
Nullable Columns: For circular dependencies to work, at least one table involved in the dependency must have a column that is nullable.
Foreign Key Dependencies and Table Constraints: While a sync job does not modify table constraints, it synchronizes data based on foreign key dependencies.
Data Insertion and Updating Process: Sync jobs first performs an initial data insertion. Subsequently, it updates the columns involved in the circular dependency.
Generate Job
In Neosync, handling circular dependencies in a Generate Job involves a few key concepts:
Support for Circular Dependencies: Generate jobs currently do not handle circular dependencies. If the schema has a self referencing circular dependency and that column is nullable then use the Null transformer.
CLI - Sync cmd
In Neosync, handling circular dependencies in a CLI Sync cmd involves a few key concepts:
Support for Circular Dependencies: The CLI sync feature in Neosync is capable of managing both self-referencing circular dependencies and those involving multiple tables. In scenarios where the source data is not from a SQL database (like AWS S3) but the destination is a SQL database, Neosync utilizes the foreign key constraints of the destination SQL database to effectively insert data. This approach ensures data integrity and respects the relational structure of the SQL database.
Nullable Columns: For circular dependencies to work, at least one table involved in the dependency must have a column that is nullable.
Foreign Key Dependencies and Table Constraints: While a CLI sync does not modify table constraints, it synchronizes data based on foreign key dependencies.
Data Insertion and Updating Process: Sync jobs first performs an initial data insertion. Subsequently, it updates the columns involved in the circular dependency.